

Teil 1: Einleitung - Datenaufbereitung mit Python
Um einen ganzheitlichen Blick auf die Strukturen und Herausforderungen einer kommunalen Bildungslandschaft zu gewinnen, arbeitet das Kommunale Bildungsmonitoring mit Daten aus einer Vielzahl von unterschiedlichen Quellen. Aus diesem Umstand ergeben sich hohe Anforderungen an das Datenmanagement, denn idealerweise werden diese Daten nicht einfach bloß angehäuft, sondern so miteinander verknüpft, dass sie eine aussagekräftige und in sich kohärente Grundlage für die kommunale Bildungsgestaltung liefern. Datenbanklösungen wie komBi können dabei helfen, diese Integration technisch umzusetzen, indem sie einen zentralen Knotenpunkt bereitstellen, an dem sich große Mengen bildungsbezogener Daten nach einem einheitlichen Schema zusammenführen lassen. Die Voraussetzung dafür: Rohdaten, die ganz unterschiedlich formatiert und strukturiert vorliegen, müssen zuvor in ein genau definiertes Zielformat umgewandelt werden. Selbstentwickelte Tools wie das vorliegende Python-Skript können dabei helfen, den Zeitaufwand für diese Datenaufbereitung zu reduzieren und leisten somit einen wertvollen Beitrag zu einem effizienten Datenmanagement. Doch auch für Fachkräfte, die überwiegend mit Excel arbeiten und regelmäßig vor der Aufgabe stehen, aufwendig vorstrukturierte Tabellen in funktionierende Pivottabellen umzuwandeln, können passgenau entwickelte Skripte eine große Arbeitsentlastung darstellen.
Wir werden dies im vorliegenden Beispiel anhand der Monatszahlen zu den Leistungsberechtigten mit Anspruch auf Leistungen zu Bildung und Teilhabe veranschaulichen, welche die Bundesagentur für Arbeit auf ihrem Online-Portal zum Download anbietet. Für ein kommunales Bildungsmonitoring, das sich für die sozialen Rahmenbedingungen der Bildungslandschaft vor Ort interessiert, liefert dieser Datensatz unter Umständen eine interessante Kennzahl. Möchte man diese nun in eine Datenbanksoftware wie komBi integrieren, stellt sich das Problem, dass die über das oben verlinkte Online-Portal abrufbaren Excel-Dateien sehr stark vorstrukturiert sind. Neben einer Reihe von Formatierungseinstellungen, Grafiken und Erläuterungstexten, die zur Umwandlung der Datei in eine Datenbanktabelle entfernt werden müssen, betrifft dies vor allem die Spaltenstruktur der Tabelle: Um unser Datenmaterial optimal für die Weiterverarbeitung in komBi aufzubereiten, wollen wir die quantitativen Daten - in der Ausgangstabelle nach Altersgruppen auf mehrere Spalten aufgeteilt - in einer einzigen Kennzahlenspalte zusammenführen:
Ihr Ansprechpartner bei Rückfragen

Weiterführende Links
Nach über 30 Jahren Entwicklung hat sich um die Programmiersprache Python im Internet eine sehr aktive Anwendergemeinschaft formiert. So gibt es heute kaum ein Syntax-Problem, auf das sich nicht mittels einer einfachen Google-Suche innerhalb von Minuten die passende Lösung finden lässt. Die nachfolgenden Links sind daher nur als Einblick in die umfangreiche Dokumentation rund um Python zu verstehen:
- Pandas User Guide des Pandas Development Team // Eine wichtige Ressource für jeden, der sich mit der Entwicklung eigener Skripte beschäftigt: Die ausführliche und fortlaufend aktualisierte Dokumentation der Pandas-Bibliothek.
- Python Excel Tutorial: The Definitive Guide von Karlijn Willems // Eine Anleitung speziell für die verzahnte Nutzung von Excel und Python.
- Pandas Cheat Sheet von Irv Lustig // Ein hilfreicher „Spickzettel“ mit häufig verwendeten Befehlen für die Arbeit mit der Pandas-Bibliothek.
- Jupyter Notebook Tutorial: The Definitive Guide von Karlijn Willems // Eine tiefergehende Einführung in die Bedienung und die Einsatzmöglichkeiten von Jupyter Notebooks.
- The Python Tutorial der Python Software Foundation // Ein umfassendes Benutzerhandbuch zur Einführung in die Programmiersprache Python.
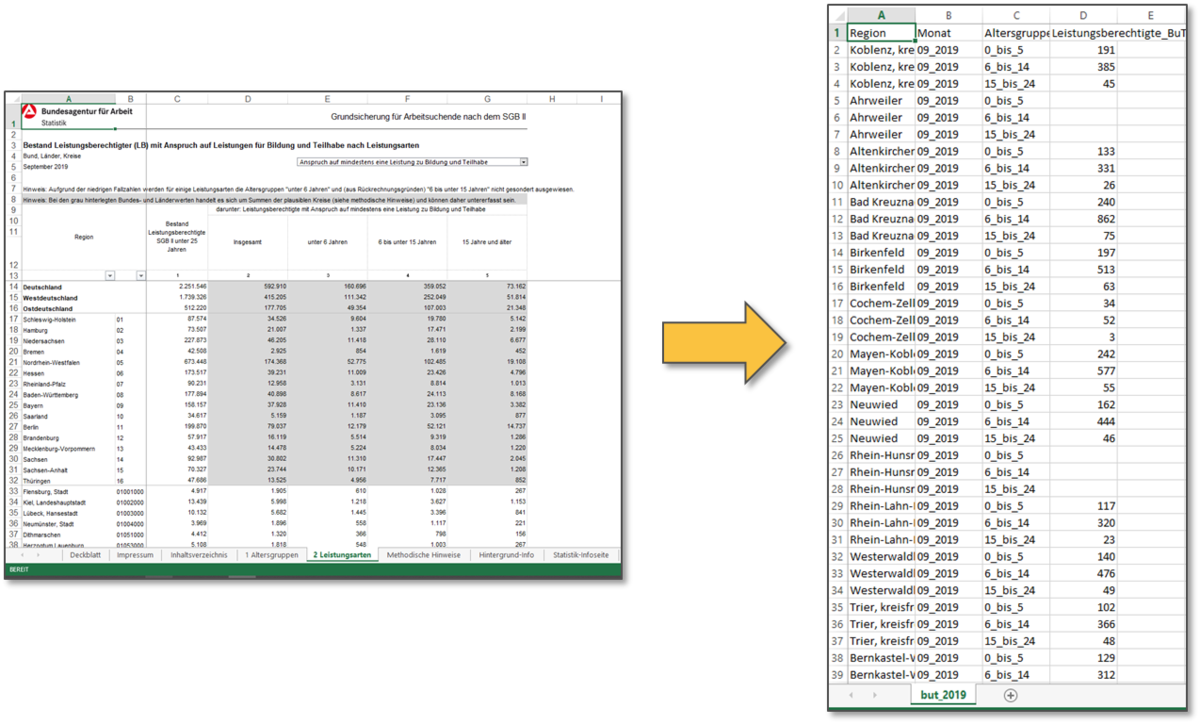
Abb. 1: Links die Ausgangstabelle der Statistik der Bundesagentur für Arbeit (https://statistik.arbeitsagentur.de/), rechts die Tabelle im Zielformat
Hinzu kommt, dass die Daten über das oben verlinkte Online-Portal nur jeweils für einen einzelnen Erhebungsmonat bereitgestellt werden. Möchte man Daten aus mehreren Monaten zu einer Zeitreihe verknüpfen, steht man daher vor der Aufgabe, die entsprechenden Dateien einzeln herunterzuladen und in einem zeitaufwendigen (und fehleranfälligen) Prozess jeweils nach dem exakt gleichen Schema in eine Datenbanktabelle umzuformen. Wird dabei manuell vorgegangen, kann diese Aufgabe ab einer gewissen Anzahl von Tabellen durchaus mehrere Stunden Zeit in Anspruch nehmen - Zeit, die bei der Analyse der Daten wohl sinnvoller investiert wäre und die wir mit selbstentwickelten Skripten zu großen Teilen einsparen können.
Teil 2: Mit Jupyter Notebooks Skripte für die Datenaufbereitung erstellen
Für das Erstellen unseres Skripts nutzen wir in diesem Beispiel eine browserbasierte Open Source Software namens Jupyter Notebook. Der zweite Teil des Tutorials leitet sie Schritt für Schritt durch den Installationsprozess und erklärt die grundlegenden Bedienungsfunktionen.
Das Jupyter Notebook ist eine interaktive Entwicklungsumgebung u.a. für die Programmiersprache Python, die aufgrund ihrer eingängigen Syntax in den vergangenen Jahren eine rasche Verbreitung in datenintensiven Tätigkeitsfeldern gefunden hat. (Quelle) Jupyter Notebooks erlauben es dem Anwender, ihren Python-Code in interaktiven Notebooks zu schreiben, zu kommentieren und auszuführen. Das Besondere daran: Das Ergebnis jedes einzelnen Code-Bausteins - wir benutzen im weiteren Verlauf den Begriff input-Feld - wird dem Anwender unmittelbar nach der Ausführung in einem output-Feld angezeigt:
In [1]:
a = 1
b = 2
a + b
Out [1]:
3
Diese intuitive und responsive Form der Befehlseingabe erleichtert insbesondere Nutzern ohne bisherige Programmiererfahrung den Einstieg in die Erstellung eigener Skripte. Ein weiterer Vorteil: Obwohl es sich um eine browserbasierte Software handelt, die auf jedem Endgerät installiert werden kann, werden die Notebooks als lokale Dateien mit der Endung .ipynb auf der Festplatte des Anwenders gespeichert. (Quelle)
Alternative Entwicklungsumgebunden für Python, die sich ebenfalls für das Entwickeln von Datenaufbereitsskripten eignen, finden Sie unter diesem Link.
Teil 3: Daten laden und sichten
Nachdem wir die Software installiert und - wie im Video beschrieben - ein neues Notebook auf unserer lokalen Festplatte angelegt haben, können wir damit beginnen, unsere Daten in das Notebook zu laden.
Doch bevor wir loslegen, importieren wir zunächst die Python-Bibliotheken, mit denen wir im weiteren Verlauf arbeiten werden:
- Die Bibliothek pandas enthält alle notwendigen Werkzeuge zur Transformation unseres Datensatzes
- Die Bibliothek xlrd ermöglicht uns den unkomplizierten Import von Excel-Dateien
In [2]:
import pandas
import xlrd
In einem ersten Schritt laden wir nun unsere Rohdaten in das Notebook. Wir haben schon im Vorfeld einen kurzen Blick in die Exceldatei geworfen und dabei bemerkt, dass es sich um eine Arbeitsmappe mit mehreren Datenblättern handelt. Wir benötigen für unsere Zwecke nur eines dieser Datenblätter und werden dies beim Import entsprechend berücksichtigen:
Über den Befehl pandas.read_excel() lesen wir das in der Excel-Datei but-d-0-201909-xlsx.xlsx enthaltene Datenblatt 2 Leistungsarten aus und speichern es innerhalb unseres Notebooks als ein Tabellenobjekt mit dem Namen tabelle. Mit dem kleinen Zusatz na.values=['.','*'] sorgen wir außerdem dafür, dass alle Punkte und Sterne innerhalb der Tabelle schon beim Dateiimport mit dem Wert "NaN" (Pandas' Standardzeichen für fehlende Werte) ersetzt werden. Wenn wir die fertige Tabelle später als .csv-Datei speichern, werden die Zellen mit einem "NaN"-Wert automatisch in leere Zellen umgewandelt. Wenn die Unterscheidung in fehlende und anonymisierte Werte erhalten bleiben soll oder der Anwender anders mit ihnen verfahren möchte, kann der entsprechende Zusatz entfernt werden.
Wichtige Anmerkung für den Dateiimport: Unsere Excel-Datei und das Notebook, mit dem wir arbeiten, müssen sich in demselben Verzeichnis befinden. Andernfalls muss in den Klammern nicht bloß der Dateiname, sondern der genaue Dateipfad zur Exceldatei angegeben werden.
Zusammengefasst lautet der Befehl für den Datenimport in unserem Fall also folgendermaßen:
In [3]:
tabelle = pandas.read_excel('but-d-0-201909-xlsx.xlsx', sheet_name = '2 Leistungsarten', na_values = ['.','*'])
Als nächstes möchten wir uns einen ersten Eindruck über den Aufbau der Tabelle verschaffen. Mit dem Befehl tabelle.head(20) lassen wir uns deshalb die ersten 20 Zeilen unserer Tabelle anzeigen:
In [4]:
tabelle.head(20)
Out [4]:
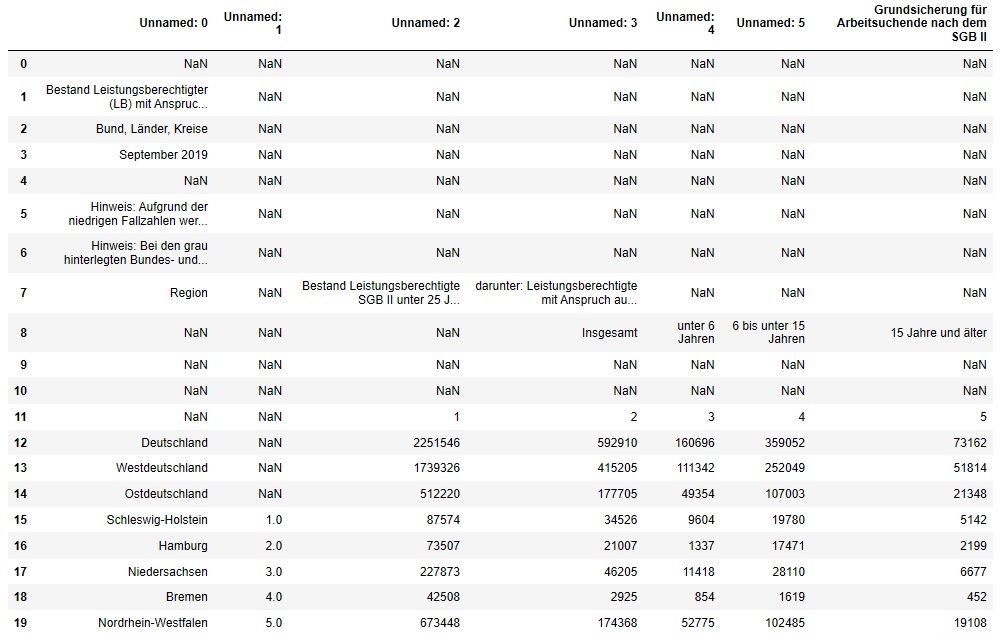
Schon auf den ersten Blick sehen wir eine sehr unaufgeräumte Tabelle mit vielen leeren Zellen, Sonderzeichen, überflüssigen Zeilen, unbenannten Spaltenköpfen usw. Wir merken uns diese Beobachtungen genau, denn auf ihrer Grundlage werden wir später unsere Tabelle umwandeln.
Dasselbe machen wir jetzt noch mit dem Tabellenende. Der Befehl tabelle.tail(10) zeigt uns die letzten 10 Zeilen der Tabelle an:
In [5]:
tabelle.tail(10)
Out [5]:
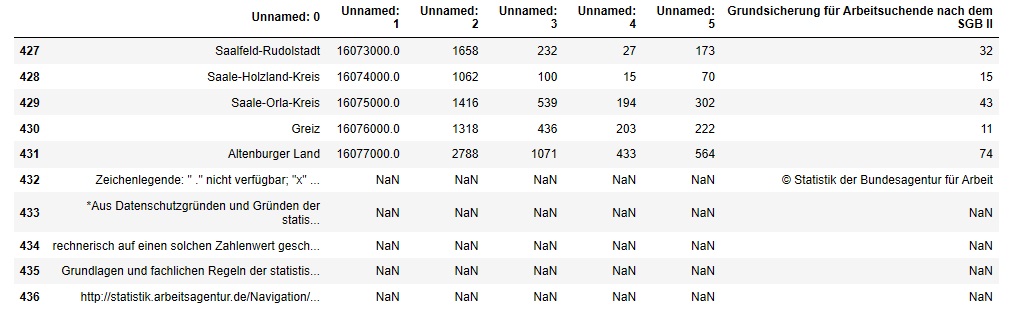
Auch am Tabellenende fallen uns fünf Zeilen auf, die für unsere finale Datenbanktabelle nicht benötigt werden und die wir ebenfalls werden entfernen müssen.
Insgesamt haben wir nun ausreichend Informationen gesammelt, um unsere Tabelle im nächsten Abschnitt grob für die weitere Verarbeitung vorzubereiten.
Teil 4: Grobe Aufräumarbeiten: Nicht benötigte Zeilen und Spalten löschen
In einem ersten Schritt zur Datenaufbereitung löschen wir nun zunächst eine Reihe überflüssiger Zeilen, um die Tabelle etwas übersichtlicher zu gestalten. Hierzu bietet Python zwei verschiedene Befehle an, die jeweils unterschiedlichen Zwecken dienen:
Große Anzahl nicht benötigter Zeilen löschen
Der Befehl .iloc[] wird verwendet, wenn eine Tabelle grob auf einen bestimmten Zeilenbereich "zugeschnitten" werden soll. In unserem Beispiel sind dies die Zeilen 7 bis 432, in denen unsere Messwerte enthalten sind. Die Informationen in den Zeilen davor und danach sind für unsere Zwecke überflüssig. Der Befehl .iloc[7:432] kann also gelesen werden als: "Nur den Zeilenbereich 7 bis 432 übernehmen".
Wie auch im weiteren Verlauf unseres Notebooks speichern wir das Ergebnis dieser Operation in einem neuen Tabellenobjekt (der tabelle1), damit unsere Ausgangstabelle nicht überschrieben wird:
In [6]:
tabelle1 = tabelle.iloc[7:432]
tabelle1
Out [6]:
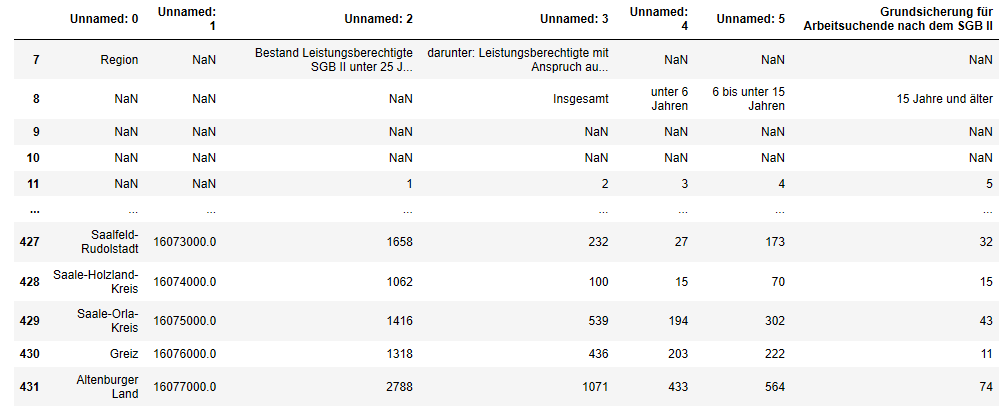
425 rows × 7 columns
Einzelne überflüssige Zeilen löschen
Der Befehl .drop() hingegen wird für feinere Anpassungen verwendet, also für das Löschen einzelner Zeilen. In unserem Fall sind dies die Zeilen 9 und 10, die keinerlei Werte enthalten. Der Zusatz axis=0 ist wichtig, da sich mit demselben Befehl auch ganze Spalten löschen lassen (nämlich mit dem Zusatz axis=1).
In [7]:
tabelle2 = tabelle1.drop([9,10], axis = 0)
tabelle2.head(15)
Out [7]:
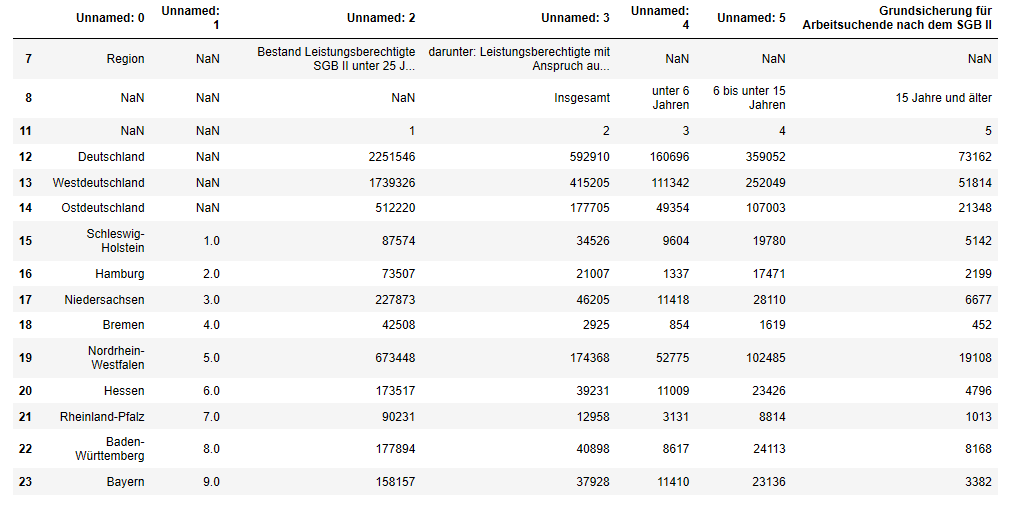
Die Tabelle ist damit schon ein wenig übersichtlicher geworden, überflüssige Zeilen am Anfang und am Ende wurden entfernt.
Nicht benötigte Spalten löschen
Als nächstes nehmen wir uns die Spalten vor und löschen in einem ersten Schritt all jene Spalten, die wir für unsere Zieltabelle nicht benötigen:
- Die Spalte "Unnamed: 1" enthält einen Regionalcode, den wir nicht weiter benötigen (alternativ könnte auch der Regionalcode beibehalten und stattdessen die Spalte "Unnamed: 0" mit den ausgeschriebenen Regionsbezeichnungen gelöscht werden).
- Die Spalte "Unnamed: 3" enthält die aggregierten Werte ohne Unterscheidung nach Altersgruppen. Diese würden in unserer Zieltabelle stören und werden deshalb ebenfalls entfernt. Wichtig: Auf diesem Wege landen wir im Ergebnis bei einer Zieltabelle, bei der (aufgrund fehlender oder anonymisierter Werte in einzelnen Zeilen) nicht für jede Gebietseinheit davon ausgegangen werden kann, dass sich die Anzahl der Leistungsberechtigten in den drei Altersgruppen zur Gesamtanzahl der tatsächlich Leistungsberechtigten summiert. Beim Laden der Daten in unsere Datenbank sollte diese Information unbedingt dokumentiert werden. Außerdem empfiehlt es sich, in den Einstellungsoptionen unserer Datenbanksoftware festzulegen, dass die Daten nicht über die Altersgruppen aggregiert werden können. Ein leicht abgewandeltes Skript, das dieses Problem auf alternative Weise behebt, finden Sie ganz am Ende dieses Notebooks.
Mit dem Befehl .drop(columns = []) löschen wir die genannten Spalten aus der Tabelle:
In [8]:
tabelle3 = tabelle2.drop(columns = ["Unnamed: 1", "Unnamed: 3"])
tabelle3.head()
Out [8]:

Die groben Aufräumarbeiten sind damit abgeschlossen. Wir können uns nun daran begeben, unsere Daten in das gewünschte Zielformat umzuformen.
Teil 5: Zieltabelle erstellen
An dieser Stelle muss nun der Anwender entscheiden, wie seine Tabelle im Ergebnis aufgebaut sein soll und welche Daten er in die fertige Tabelle übernehmen möchte. Wir entscheiden uns in diesem Beispiel dafür, die Daten zum "Bestand Leistungsberechtigte SGB II unter 25 Jahre" zu löschen und bloß die Daten zu den "Leistungsberechtigten mit Anspruch auf mindestens eine Leistung zu Bildung und Teilhabe" nach Altersgruppen zu übernehmen.
Weitere überflüssige Spalten löschen
Mit dem schon bekannten Befehl .drop() löschen wir dazu als erstes die nicht länger benötigte Spalte "Unnamed: 2" :
In [9]:
zieltabelle = tabelle3.drop(columns = ["Unnamed: 2"])
zieltabelle.head()
Out [9]:
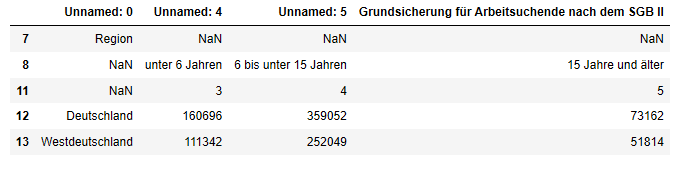
Benötigte Spalten umbenennen
Mit dem Befehl .rename() können wir nun, nachdem wir uns über den Aufbau der Zieltabelle im Klaren sind, außerdem unsere Spaltenköpfe umbenennen. Die bestehenden Spaltentitel wurden beim Dateiimport automatisch vergeben und haben bislang eher als Platzhalter fungiert.
Um genau zu steuern, welche Spalten wie umbenannt werden, spezifizieren wir unseren Befehl .rename() mit einem sogenannten "Wörterbuch", also einer Reihe von Wortpaaren nach dem Schema {"Alter Spaltenname":"Neuer Spaltenname",...}:
In [10]:
zieltabelle1 = zieltabelle.rename(columns = {"Unnamed: 0":"Region", "Unnamed: 4":"0_bis_5", "Unnamed: 5":"6_bis_14", "Grundsicherung für Arbeitsuchende nach dem SGB II":"15_bis_24"})
zieltabelle1.head()
Out [10]:
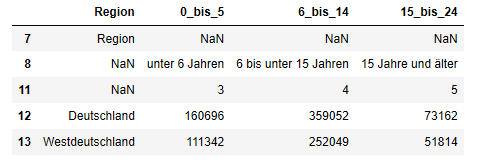
Weitere überflüssige Zeilen löschen
Nachdem wir nun die Information, welche Spalte die Daten zu welcher Altersgruppe enthält, in die Spaltenköpfe übernommen haben, werden die drei Zeilen an den Indexpositionen 7, 8 und 11 nicht länger benötigt und können mit dem Befehl .drop() ebenfalls entfernt werden:
In [11]:
zieltabelle2 = zieltabelle1.drop([7,8,11], axis = 0)
zieltabelle2.head()
Out [11]:

Das Ergebnis sieht bereits vielversprechend aus. Ein letzter Schritt, bevor wir uns an die Herstellung des gewünschten Zielformats begeben, besteht nun darin, unsere Daten mit einer Spalte für die Monatsangabe zu ergänzen. Denn wie eingangs gesagt, planen wir in diesem Beispielszenario, die fertig aufbereiteten Tabellen aus den einzelnen Monaten anschließend zu einer Zeitreihe zu verknüpfen.
Daten anreichern: Spalte einfügen und automatisch füllen
Da unsere Ausgangstabelle ohnehin nur Daten aus einem Monat enthielt, war darin keine gesonderte Spalte für den Erhebungsmonat vorgesehen. Mit dem Befehl .insert() können wir diese nachträglich einfügen und durchgehend mit dem Wert "09_2019" füllen. Die 1 in den Klammern hinter dem Befehl legt dabei fest, dass die neue Spalte an der Position 1 (also rechts neben der Spalte "Region" an der Position 0) eingefügt werden soll :
In [12]:
zieltabelle2.insert(1, "Monat", "09_2019")
zieltabelle2.head()
Out [12]:
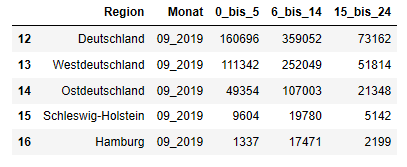
Umwandlung vom "breiten" ins "lange" Tabellenformat
Jetzt wird es interessant, denn wir beginnen nun damit, unser Daten in das "lange" Tabellenformat umzuwandeln: Im Ergebnis möchten wir eine Spalte mit unseren Messwerten erhalten (die spätere Kennzahlenspalte) und je eine weitere Spalte für jedes Differenzierungsmerkmal, nach dem unsere Daten vorliegen (die späteren "Schlüsselspalten").
Die dazu notwendige Umwandlungsoperation lässt sich schematisch folgendermaßen darstellen: Aus einer "breiten" Ausgangstabelle mit einer Spalte je Altersgruppe ...

... soll eine "lange" Zieltabelle hergestellt werden, welche die Ausprägungen des Merkmals "Altersgruppe" in einer Spalte zusammenfasst:
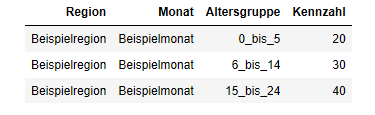
Daten in das "lange" Tabellenformat überführen
Manuell ist dieser Vorgang schon für eine Tabelle recht mühsam durchzuführen (von der Fehleranfälligkeit ganz abgesehen). Wenn aber, wie in unserem Beispiel, gleich mehrere Tabellen (nämlich eine pro Erhebungsmonat) einzeln nacheinander umgeformt werden müssen, kann dies schnell sehr viel Zeit beanspruchen - Zeit, welche die meisten Monitorer lieber für die gründliche Analyse ihrer Daten aufwenden würden.
Zum Glück lässt sich dieser Prozess mit Python sehr leicht automatisieren. Im Grunde genügen hierfür vier Zeilen Code:
- In einem ersten Schritt erstellen wir eine Liste mit den Namen von all denjenigen Merkmalsspalten, die bereits im richtigen ("langen") Format vorliegen und von der folgenden Umformung nicht berührt werden sollen. In unserem Beispiel also die Spalten "Region" und "Monat":
In [13]:
liste = ["Region", "Monat"]
2. Mit dem Befehl set_index() werden die Spalten in dieser Liste nun zum Tabellenindex erklärt und dienen uns fortan als "Anker" für die Umformung:
In [14]:
zieltabelle3 = zieltabelle2.set_index(liste)
3. In einem dritten Schritt werden mit dem Befehl .stack() die drei Spalten mit den Altersgruppen untereinander gestapelt (von englisch to stack: stapeln).
Mit dem Zusatz dropna=False verhindern wir, dass dabei Zeilen mit fehlenden Werten standardmäßig gelöscht werden:
In [15]:
zieltabelle_gestapelt = zieltabelle3.stack(dropna=False)
4. Abschließend wird mittels .reset_index() der im zweiten Schritt erstellte Index wieder in einen normalen, numerierten Tabellenindex zurückgesetzt:
In [16]:
zieltabelle_gestapelt1 = zieltabelle_gestapelt.reset_index()
zieltabelle_gestapelt1.head()
Out [16]:

Fertig! Liegen diese vier Code-Bausteine einmal vorbereitet in der Schublade, brauchen Tabellenabschnitte nicht länger manuell in Excel hin- und hergeschoben werden, sondern können innerhalb von Sekunden automatisch in das "lange" Format gebracht werden.
Im Prinzip trennen uns jetzt bloß noch die falsch benannten Spaltenköpfe von der gewünschten Zieltabelle. Wir greifen erneut zu .rename() und erhalten im Ergebnis eine Tabelle, die so bereits als CSV-Datei exportiert werden könnte:
In [17]:
zieltabelle_gestapelt2 = zieltabelle_gestapelt1.rename(columns = {"level_2":"Altersgruppe",0:"Leistungsberechtigte_BuT"})
zieltabelle_gestapelt2.head()
Out [17]:

Teil 6: Ergebnistabelle für den Export vorbereiten und im .csv-Format speichern
Sonderzeichen suchen und ersetzen
In einem vorletzten Schritt ersetzen wir jetzt noch in der Spalte "Region" alle Umlaute wie "ä" oder "ü" durch zwei einfache Vokale und verhindern dadurch, dass es später Probleme bei der Dateispeicherung im .csv-Format geben wird. Wir nutzen hierzu erneut den Befehl .replace() in Kombination mit einem Wörterbuch, das die Wortpaare für die "Suchen-Ersetzen"-Operation enthält:
In [18]:
umlaute = {"ä":"ae", "Ä":"Ae", "ö":"oe", "Ö":"Oe", "Ü":"Ue", "ü":"ue", "ß":"ss"}
zieltabelle_gestapelt2["Region"].replace(umlaute, inplace = True, regex = True)
Um das Ergebnis zu überprüfen, lassen wir uns mittels .unique() die distinkten Einträge in der Spalte "Region" anzeigen:
In [19]:
zieltabelle_gestapelt2.Region.unique()
Out [19]:
array(['Deutschland', 'Westdeutschland', 'Ostdeutschland', 'Schleswig-Holstein', 'Hamburg', 'Niedersachsen', 'Bremen', 'Nordrhein-Westfalen', 'Hessen', 'Rheinland-Pfalz', 'Baden-Wuerttemberg', 'Bayern', 'Saarland', 'Berlin', 'Brandenburg', 'Mecklenburg-Vorpommern', 'Sachsen', 'Sachsen-Anhalt', 'Thueringen', 'Flensburg, Stadt', 'Kiel, Landeshauptstadt', 'Luebeck, Hansestadt', 'Neumuenster, Stadt', 'Dithmarschen', 'Herzogtum Lauenburg', 'Nordfriesland', 'Ostholstein', 'Pinneberg', 'Ploen', 'Rendsburg-Eckernfoerde', 'Schleswig-Flensburg', 'Segeberg', 'Steinburg', 'Stormarn', 'Hamburg, Freie und Hansestadt', 'Braunschweig, Stadt', 'Salzgitter, Stadt', 'Wolfsburg, Stadt', 'Gifhorn', 'Goslar', 'Helmstedt', 'Northeim', 'Peine', 'Wolfenbuettel', 'Goettingen', 'Region Hannover', 'Diepholz', 'Hameln-Pyrmont', 'Hildesheim', 'Holzminden', 'Nienburg (Weser)', 'Schaumburg', 'Celle', 'Cuxhaven', 'Harburg', 'Luechow-Dannenberg', 'Lueneburg', 'Osterholz', 'Rotenburg (Wuemme)', 'Heidekreis', 'Stade', 'Uelzen', 'Verden', 'Delmenhorst, Stadt', 'Emden, Stadt', 'Oldenburg (Oldenburg), Stadt', 'Osnabrueck, Stadt', 'Wilhelmshaven, Stadt', 'Ammerland', 'Aurich', 'Cloppenburg', 'Emsland', 'Friesland', 'Grafschaft Bentheim', 'Leer', 'Oldenburg', 'Osnabrueck', 'Vechta', 'Wesermarsch', 'Wittmund', 'Bremen, Stadt', 'Bremerhaven, Stadt', 'Duesseldorf, Stadt', 'Duisburg, Stadt', 'Essen, Stadt', 'Krefeld, Stadt', 'Moenchengladbach, Stadt', 'Muelheim an der Ruhr, Stadt', 'Oberhausen, Stadt', 'Remscheid, Stadt', 'Solingen, Klingenstadt', 'Wuppertal, Stadt', 'Kleve', 'Mettmann', 'Rhein-Kreis Neuss', 'Viersen', 'Wesel', 'Bonn, Stadt', 'Koeln, Stadt', 'Leverkusen, Stadt', 'Staedteregion Aachen', 'Dueren', 'Rhein-Erft-Kreis', 'Euskirchen', 'Heinsberg', 'Oberbergischer Kreis', 'Rheinisch-Bergischer Kreis', 'Rhein-Sieg-Kreis', 'Bottrop, Stadt', 'Gelsenkirchen, Stadt', 'Muenster, Stadt', 'Borken', 'Coesfeld', 'Recklinghausen', 'Steinfurt', 'Warendorf', 'Bielefeld, Stadt', 'Guetersloh', 'Herford', 'Hoexter', 'Lippe', 'Minden-Luebbecke', 'Paderborn', 'Bochum, Stadt', 'Dortmund, Stadt', 'Hagen, Stadt der FernUniversi.', 'Hamm, Stadt', 'Herne, Stadt', 'Ennepe-Ruhr-Kreis', 'Hochsauerlandkreis', 'Maerkischer Kreis', 'Olpe', 'Siegen-Wittgenstein', 'Soest', 'Unna', 'Darmstadt, Wissenschaftsstadt', 'Frankfurt am Main, Stadt', 'Offenbach am Main, Stadt', 'Wiesbaden, Landeshauptstadt', 'Bergstrasse', 'Darmstadt-Dieburg', 'Gross-Gerau', 'Hochtaunuskreis', 'Main-Kinzig-Kreis', 'Main-Taunus-Kreis', 'Odenwaldkreis', 'Offenbach', 'Rheingau-Taunus-Kreis', 'Wetteraukreis', 'Giessen', 'Lahn-Dill-Kreis', 'Limburg-Weilburg', 'Marburg-Biedenkopf', 'Vogelsbergkreis', 'Kassel, documenta-Stadt', 'Fulda', 'Hersfeld-Rotenburg', 'Kassel', 'Schwalm-Eder-Kreis', 'Waldeck-Frankenberg', 'Werra-Meissner-Kreis', 'Koblenz, kreisfreie Stadt', 'Ahrweiler', 'Altenkirchen (Westerwald)', 'Bad Kreuznach', 'Birkenfeld', 'Cochem-Zell', 'Mayen-Koblenz', 'Neuwied', 'Rhein-Hunsrueck-Kreis', 'Rhein-Lahn-Kreis', 'Westerwaldkreis', 'Trier, kreisfreie Stadt', 'Bernkastel-Wittlich', 'Eifelkreis Bitburg-Pruem', 'Vulkaneifel', 'Trier-Saarburg', 'Frankenthal (Pfalz), kr.f. St.', 'Kaiserslautern, kreisfr. Stadt', 'Landau in der Pfalz, kr.f. St.', 'Ludwigshafen am Rhein, Stadt', 'Mainz, kreisfreie Stadt', 'Neustadt an der Weinstrasse,St.', 'Pirmasens, kreisfreie Stadt', 'Speyer, kreisfreie Stadt', 'Worms, kreisfreie Stadt', 'Zweibruecken, kreisfreie Stadt', 'Alzey-Worms', 'Bad Duerkheim', 'Donnersbergkreis', 'Germersheim', 'Kaiserslautern', 'Kusel', 'Suedliche Weinstrasse', 'Rhein-Pfalz-Kreis', 'Mainz-Bingen', 'Suedwestpfalz', 'Stuttgart, Landeshauptstadt', 'Boeblingen', 'Esslingen', 'Goeppingen', 'Ludwigsburg', 'Rems-Murr-Kreis', 'Heilbronn, Stadt', 'Heilbronn', 'Hohenlohekreis', 'Schwaebisch Hall', 'Main-Tauber-Kreis', 'Heidenheim', 'Ostalbkreis', 'Baden-Baden, Stadt', 'Karlsruhe, Stadt', 'Karlsruhe', 'Rastatt', 'Heidelberg, Stadt', 'Mannheim, Universitaetsstadt', 'Neckar-Odenwald-Kreis', 'Rhein-Neckar-Kreis', 'Pforzheim, Stadt', 'Calw', 'Enzkreis', 'Freudenstadt', 'Freiburg im Breisgau, Stadt', 'Breisgau-Hochschwarzwald', 'Emmendingen', 'Ortenaukreis', 'Rottweil', 'Schwarzwald-Baar-Kreis', 'Tuttlingen', 'Konstanz', 'Loerrach', 'Waldshut', 'Reutlingen', 'Tuebingen', 'Zollernalbkreis', 'Ulm, Universitaetsstadt', 'Alb-Donau-Kreis', 'Biberach', 'Bodenseekreis', 'Ravensburg', 'Sigmaringen', 'Ingolstadt, Stadt', 'Muenchen, Landeshauptstadt', 'Rosenheim, Stadt', 'Altoetting', 'Berchtesgadener Land', 'Bad Toelz-Wolfratshausen', 'Dachau', 'Ebersberg', 'Eichstaett', 'Erding', 'Freising', 'Fuerstenfeldbruck', 'Garmisch-Partenkirchen', 'Landsberg am Lech', 'Miesbach', 'Muehldorf a.Inn', 'Muenchen', 'Neuburg-Schrobenhausen', 'Pfaffenhofen a.d.Ilm', 'Rosenheim', 'Starnberg', 'Traunstein', 'Weilheim-Schongau', 'Landshut, Stadt', 'Passau, Stadt', 'Straubing, Stadt', 'Deggendorf', 'Freyung-Grafenau', 'Kelheim', 'Landshut', 'Passau', 'Regen', 'Rottal-Inn', 'Straubing-Bogen', 'Dingolfing-Landau', 'Amberg, Stadt', 'Regensburg, Stadt', 'Weiden i.d.OPf., Stadt', 'Amberg-Sulzbach', 'Cham', 'Neumarkt i.d.OPf.', 'Neustadt a.d.Waldnaab', 'Regensburg', 'Schwandorf', 'Tirschenreuth', 'Bamberg, Stadt', 'Bayreuth, Stadt', 'Coburg, Stadt', 'Hof, Stadt', 'Bamberg', 'Bayreuth', 'Coburg', 'Forchheim', 'Hof', 'Kronach', 'Kulmbach', 'Lichtenfels', 'Wunsiedel i.Fichtelgebirge', 'Ansbach, Stadt', 'Erlangen, Stadt', 'Fuerth, Stadt', 'Nuernberg, Stadt', 'Schwabach, Stadt', 'Ansbach', 'Erlangen-Hoechstadt', 'Fuerth', 'Nuernberger Land', 'Neustadt a.d.Aisch-Bad Windsh.', 'Roth', 'Weissenburg-Gunzenhausen', 'Aschaffenburg, Stadt', 'Schweinfurt, Stadt', 'Wuerzburg, Stadt', 'Aschaffenburg', 'Bad Kissingen', 'Rhoen-Grabfeld', 'Hassberge', 'Kitzingen', 'Miltenberg', 'Main-Spessart', 'Schweinfurt', 'Wuerzburg', 'Augsburg, Stadt', 'Kaufbeuren, Stadt', 'Kempten (Allgaeu), Stadt', 'Memmingen, Stadt', 'Aichach-Friedberg', 'Augsburg', 'Dillingen a.d.Donau', 'Guenzburg', 'Neu-Ulm', 'Lindau (Bodensee)', 'Ostallgaeu', 'Unterallgaeu', 'Donau-Ries', 'Oberallgaeu', 'Regionalverband Saarbruecken', 'Merzig-Wadern', 'Neunkirchen', 'Saarlouis', 'Saarpfalz-Kreis', 'St. Wendel', 'Berlin, Stadt', 'Brandenburg an der Havel, St.', 'Cottbus, Stadt', 'Frankfurt (Oder), Stadt', 'Potsdam, Stadt', 'Barnim', 'Dahme-Spreewald', 'Elbe-Elster', 'Havelland', 'Maerkisch-Oderland', 'Oberhavel', 'Oberspreewald-Lausitz', 'Oder-Spree', 'Ostprignitz-Ruppin', 'Potsdam-Mittelmark', 'Prignitz', 'Spree-Neisse', 'Teltow-Flaeming', 'Uckermark', 'Rostock, Hansestadt', 'Schwerin, Landeshauptstadt', 'Mecklenburgische Seenplatte', 'Landkreis Rostock', 'Vorpommern-Ruegen', 'Nordwestmecklenburg', 'Vorpommern-Greifswald', 'Ludwigslust-Parchim', 'Chemnitz, Stadt', 'Erzgebirgskreis', 'Mittelsachsen', 'Vogtlandkreis', 'Zwickau', 'Dresden, Stadt', 'Bautzen', 'Goerlitz', 'Meissen', 'Saechs. Schweiz-Osterzgebirge', 'Leipzig, Stadt', 'Leipzig', 'Nordsachsen', 'Dessau-Rosslau, Stadt', 'Halle (Saale), Stadt', 'Magdeburg, Landeshauptstadt', 'Altmarkkreis Salzwedel', 'Anhalt-Bitterfeld', 'Boerde', 'Burgenlandkreis', 'Harz', 'Jerichower Land', 'Mansfeld-Suedharz', 'Saalekreis', 'Salzlandkreis', 'Stendal', 'Wittenberg', 'Erfurt, Stadt', 'Gera, Stadt', 'Jena, Stadt', 'Suhl, Stadt', 'Weimar, Stadt', 'Eisenach, Stadt', 'Eichsfeld', 'Nordhausen', 'Wartburgkreis', 'Unstrut-Hainich-Kreis', 'Kyffhaeuserkreis', 'Schmalkalden-Meiningen', 'Gotha', 'Soemmerda', 'Hildburghausen', 'Ilm-Kreis', 'Weimarer Land', 'Sonneberg', 'Saalfeld-Rudolstadt', 'Saale-Holzland-Kreis', 'Saale-Orla-Kreis', 'Greiz', 'Altenburger Land'], dtype=object)
Als letzten Schritt vor dem Datei-Export gehen wir in unserem Beispiel davon aus, dass die fertige Datei nicht sämtliche Daten enthalten soll, sondern nur jene für die Kreise und kreisfreien Städte im Bundesland Rheinland-Pfalz. Kurz: Wir wollen die Tabelle vor dem Speichern filtern.
Wenn sämtliche Daten in der Tabelle übernommen werden sollen, könnte dieser Schritt theoretisch entfallen. Für die Weiterverarbeitung der Daten in komBi sollte jedoch in jedem Fall darauf geachtet werden, dass die Daten in der fertigen Tabelle nur auf der niedrigsten verfügbaren Raumebene vorliegen.
Tabelle nach bestimmten Werten filtern
Python bietet eine Vielzahl von Methoden an, um Tabellen zu filtern - je nach dem, ob sehr komplexe oder eher allgemeine Filteranweisungen formuliert werden, ob die gefilterten Werte gelöscht oder bloß "ausgeblendet" werden sollen etc.
In unserem Beispiel möchten wir eine relativ große Anzahl an Werten (nämlich die Namen der 36 Kreise und kreisfreien Städte in Rheinland-Pfalz) als Filterkriterien auf die Spalte "Region" anwenden. Wir entscheiden uns deshalb dafür, diese Werte zunächst in einer Liste namens liste_rlp zu speichern und mit dem Befehl .isin() anschließend den Abgleich zwischen der Liste und der Tabellenspalte "Region" zu vollziehen.
Im Ergebnis erhalten wir eine gefilterte Tabelle, die bloß noch die jene Zeilen enthält, bei denen es eine Übereinstimmung zwischen den Einträgen der liste_rlp und den Werten der Tabellenspalte "Region" gab:
In [20]:
liste_rlp = ['Koblenz, kreisfreie Stadt','Ahrweiler','Altenkirchen (Westerwald)','Bad Kreuznach','Birkenfeld','Cochem-Zell','Mayen-Koblenz','Neuwied','Rhein-Hunsrueck-Kreis','Rhein-Lahn-Kreis','Westerwaldkreis','Trier, kreisfreie Stadt','Bernkastel-Wittlich','Eifelkreis Bitburg-Pruem','Vulkaneifel','Trier-Saarburg','Frankenthal (Pfalz), kr.f. St.','Kaiserslautern, kreisfr. Stadt','Landau in der Pfalz, kr.f. St.','Ludwigshafen am Rhein, Stadt','Mainz, kreisfreie Stadt','Neustadt an der Weinstrasse,St.','Pirmasens, kreisfreie Stadt','Speyer, kreisfreie Stadt','Worms, kreisfreie Stadt','Zweibruecken, kreisfreie Stadt','Alzey-Worms','Bad Duerkheim','Donnersbergkreis','Germersheim','Kaiserslautern','Kusel','Suedliche Weinstraße','Rhein-Pfalz-Kreis','Mainz-Bingen','Suedwestpfalz']
but_rlp = zieltabelle_gestapelt2[zieltabelle_gestapelt2["Region"].isin(liste_rlp)]
but_rlp.head(10)
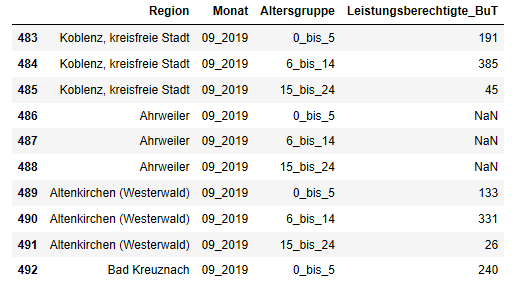
Fertige Tabelle als csv-Datei exportieren
Abschließend wird die fertige Tabelle mit dem Befehl .to_csv() exportiert. Der Zusatz index=False sorgt dafür, dass der nummerierte Tabellenindex nicht in die finale csv-Datei übernommen wird, während der Ausdruck sep = ";" das Semikolon als das Trennungszeichen für die Datenfelder der csv-Datei definiert.
Nach Ausführung des Befehls erscheint die Tabelle sofort als CSV-Datei mit dem Namen "but_2019.csv" in unserem Notebook-Verzeichnis:
In [21]:
but_rlp.to_csv("but_2019.csv", index = False, sep = ";")
Teil 7: Skript als fertige Schablone zusammenfassen
Skripte werden vorrangig dann entwickelt, wenn es darum geht, ...
- eine große Anzahl nahezu identisch aufgebauter Tabellen auf einmal umzuwandeln
- die Aufbereitung eines Datensatzes zu automatisieren, der fortlaufend mit neuen Daten aktualisiert wird
In beiden Fällen rentiert sich der Zeitaufwand für die Skriptentwicklung dadurch, dass das Skript mehrfach und/oder fortlaufend verwendet wird. Um bei unserem Beispiel zu bleiben: Liegt das Skript erstmal vor, braucht man beim Erscheinen der aktuellen Monatszahlen zu den BuT-Leistungsberechtigen bloß noch minimale Änderungen am Skript vorzunehmen und kann die neue Datei anschließend innerhalb von Sekunden in das definierte Zielformat umwandeln.
Um dabei möglichst effizient vorzugehen, werden sich die meisten Anwender ihr Skript nicht in der oben dargelegten Form - mit ausführlicher Kommentierung und auf viele kurze Blöcke aufgeteilt - speichern, sondern in einer zusammengefassten Form, die bloß kurze Hinweise auf die anzupassenden Parameter enthält. Unten finden Sie deshalb den oben kleinteilig besprochenen Code (abzüglich der Befehle, die uns die Zwischenergebnisse anzeigen) nochmal in der Gesamtschau:
In [22]:
import pandas
import xlrd
# In der nächsten Zeile den Dateinamen anpassen
tabelle = pandas.read_excel('but-d-0-201909-xlsx.xlsx', sheet_name = '2 Leistungsarten', na_values = ['.','*'])
tabelle1 = tabelle.iloc[7:432]
tabelle2 = tabelle1.drop([9,10], axis = 0)
tabelle3 = tabelle2.drop(columns = ['Unnamed: 1', 'Unnamed: 3'])
zieltabelle = tabelle3.drop(columns = ["Unnamed: 2"])
zieltabelle1 = zieltabelle.rename(columns = {"Unnamed: 0":"Region", "Unnamed: 4":"0_bis_5", "Unnamed: 5":"6_bis_14", "Grundsicherung für Arbeitsuchende nach dem SGB II":"15_bis_24"})
zieltabelle2 = zieltabelle1.drop([7,8,11], axis = 0)
# In der nächsten Zeile die Jahres- und Monatsangaben anpassen
zieltabelle2.insert(1, "Monat", "09_2019")
liste = ["Monat", "Region"]
zieltabelle3 = zieltabelle2.set_index(liste)
zieltabelle_gestapelt = zieltabelle3.stack(dropna = False)
zieltabelle_gestapelt1 = zieltabelle_gestapelt.reset_index()
zieltabelle_gestapelt2 = zieltabelle_gestapelt1.rename(columns = {"level_2":"Altersgruppe",0:"Leistungsberechtigte_BuT"})
umlaute = {"ä":"ae", "Ä":"Ae", "ö":"oe", "Ö":"Oe", "Ü":"Ue", "ü":"ue", "ß":"ss"}
zieltabelle_gestapelt2["Region"].replace(umlaute, inplace = True, regex = True)
liste_rlp = ['Koblenz, kreisfreie Stadt','Ahrweiler','Altenkirchen (Westerwald)','Bad Kreuznach','Birkenfeld','Cochem-Zell','Mayen-Koblenz','Neuwied','Rhein-Hunsrueck-Kreis','Rhein-Lahn-Kreis','Westerwaldkreis','Trier, kreisfreie Stadt','Bernkastel-Wittlich','Eifelkreis Bitburg-Pruem','Vulkaneifel','Trier-Saarburg','Frankenthal (Pfalz), kr.f. St.','Kaiserslautern, kreisfr. Stadt','Landau in der Pfalz, kr.f. St.','Ludwigshafen am Rhein, Stadt','Mainz, kreisfreie Stadt','Neustadt an der Weinstrasse,St.','Pirmasens, kreisfreie Stadt','Speyer, kreisfreie Stadt','Worms, kreisfreie Stadt','Zweibruecken, kreisfreie Stadt','Alzey-Worms','Bad Duerkheim','Donnersbergkreis','Germersheim','Kaiserslautern','Kusel','Suedliche Weinstraße','Rhein-Pfalz-Kreis','Mainz-Bingen','Suedwestpfalz']
but_rlp = zieltabelle_gestapelt2[zieltabelle_gestapelt2["Region"].isin(liste_rlp)]
# In der nächsten Zeile den Dateinamen anpassen
but_rlp.to_csv("but_rlp_2019.csv", index = False, sep = ";")
Das oben zusammengefasste Skript kann nun verwendet werden, um die heruntergeladenen Excel-Dateien mit den Daten der einzelnen Erhebungszeiträume rasch in das gewünschte, einheitliche Zielformat umzuwandeln. Die einzeln gespeicherten CSV-Dateien können anschließend in einer finalen Tabelle zusammengefasst und als Indikator in komBi angelegt werden.
Anhang: Alternative Lösung zum Umgang mit den Missing Values
Im Abschnitt Grobe Aufräumarbeiten: Nicht benötigte Zeilen und Spalten löschen wurde auf das Problem hingewiesen, dass die fertige Tabelle aufgrund fehlender und/oder anonymisierter Werte in einigen Fällen keine zuverlässige Aggregation über die Altergsgruppen erlaubt: Die Summe der Leistungsberechtigten in den drei Altersgruppen ergibt nicht für jede Kommune die tatsächliche Gesamtzahl der Leistungsberechtigten. Bei der Weiterverarbeitung der Daten in komBi sollte dieser Hinweis unbedingt dokumentiert werden.
Eine alternative Lösung besteht darin, der Tabelle in der Spalte "Altersgruppen" eine künstliche Ausprägung namens "nz" (Abkürzung für "nicht zuzuordnen") hinzuzufügen, in der die Anzahl der fehlenden und anonymisierten Werte (also die Differenz zwischen der Gesamtzahl und der Summe der drei Altergruppen) berechnet wird. Die Summe dieser vier Ausprägungen (drei Altersgruppen + "nz") ergibt dann in jedem Fall die korrekte Gesamtzahl, was eine Aggregation über die Altersgruppen prinzipiell möglich macht.
Wir übernehmen dazu einfach den oben entwickelten Code bis zur Erstellung der "zieltabelle2" und achten darauf, in diesem Fall die Spalte mit den Gesamtwerten vorerst nicht zu entfernen:
In [23]:
tabelle = pandas.read_excel('but-d-0-201909-xlsx.xlsx', sheet_name = '2 Leistungsarten', na_values = ['.','*'])
tabelle1 = tabelle.iloc[7:432]
tabelle2 = tabelle1.drop([9,10], axis = 0)
tabelle3 = tabelle2.drop(columns = ['Unnamed: 1'])
zieltabelle = tabelle3.drop(columns = ["Unnamed: 2"])
zieltabelle1 = zieltabelle.rename(columns = {"Unnamed: 3":"Insgesamt", "Unnamed: 0":"Region", "Unnamed: 4":"0_bis_5", "Unnamed: 5":"6_bis_14", "Grundsicherung für Arbeitsuchende nach dem SGB II":"15_bis_24"})
zieltabelle2 = zieltabelle1.drop([7,8,11], axis = 0)
zieltabelle2.head()
Out [23]:
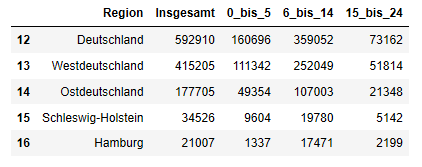
Noch bevor wir die Tabelle in das "flache" Zielformat umwandeln, erweitern wir dann unsere Tabelle um eine weitere Spalte, in der wir die Differenz zwischen der Spalte "Insgesamt" und den Spalten der drei Altersgruppen berechnen:
In [24]:
# Wir kopieren die Tabelle in ein neues Tabellenobjekt namens "tabelle_nan"
tabelle_nan = zieltabelle2
# Wir löschen all jene Zeilen, in denen noch nicht einmal die Gesamtwerte vorliegen:
tabelle_nan1 = tabelle_nan.dropna(axis = 0, subset = ['Insgesamt'])
# Die verbliebenen NaN-Werte in der Tabelle werden durch den Wert "0" ersetzt, damit anschließend mit ihnen gerechnet werden kann:
tabelle_nan2 = tabelle_nan1.fillna(0)
# Wir ergänzen eine neue Spalte namens "nz", welche die Differenz zwischen der "Insgesamt"-Spalte und der Summe der drei Altersgruppen-Spalten enthält:
tabelle_nan2["nz"] = tabelle_nan2["Insgesamt"] - tabelle_nan2["0_bis_5"] - tabelle_nan2["6_bis_14"] - tabelle_nan2["15_bis_24"]
# Wir entfernen die Spalte mit den aggregierten Werten:
tabelle_nan3 = tabelle_nan2.drop(columns = ["Insgesamt"])
tabelle_nan3.tail()
Out [24]:
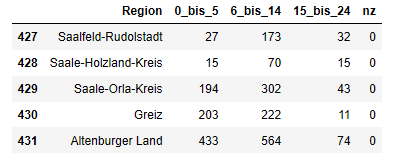
Anschließend fahren wir weitgehend genauso fort, wie mit der ursprünglichen Tabelle: Die Monatsspalte wird ergänzt, die Tabelle ins "lange" Zielformat umgewandelt und abschließend gefiltert:
In [25]:
tabelle_nan3.insert(1, "Monat", "09_2019")
liste = ["Monat", "Region"]
zieltabelle3 = tabelle_nan3.set_index(liste)
zieltabelle_gestapelt = zieltabelle3.stack(dropna = False)
zieltabelle_gestapelt1 = zieltabelle_gestapelt.reset_index()
zieltabelle_gestapelt2 = zieltabelle_gestapelt1.rename(columns = {"level_2":"Altersgruppe",0:"Leistungsberechtigte_BuT"})
# Mit der folgenden Zeile löschen wir alle Zeilen, bei denen in der Kennzahlenspalte der Wert "0" übrig geblieben ist:
zieltabelle_gestapelt3 = zieltabelle_gestapelt2[zieltabelle_gestapelt2.Leistungsberechtigte_BuT != 0]
# Anschließend fahren wir wie bei der ursprünglichen Variante fort:
umlaute = {"ä":"ae", "Ä":"Ae", "ö":"oe", "Ö":"Oe", "Ü":"Ue", "ü":"ue", "ß":"ss"}
zieltabelle_gestapelt4 = zieltabelle_gestapelt3.copy()
zieltabelle_gestapelt4["Region"].replace(umlaute, inplace = True, regex = True)
liste_rlp = ['Koblenz, kreisfreie Stadt','Ahrweiler','Altenkirchen (Westerwald)','Bad Kreuznach','Birkenfeld','Cochem-Zell','Mayen-Koblenz','Neuwied','Rhein-Hunsrueck-Kreis','Rhein-Lahn-Kreis','Westerwaldkreis','Trier, kreisfreie Stadt','Bernkastel-Wittlich','Eifelkreis Bitburg-Pruem','Vulkaneifel','Trier-Saarburg','Frankenthal (Pfalz), kr.f. St.','Kaiserslautern, kreisfr. Stadt','Landau in der Pfalz, kr.f. St.','Ludwigshafen am Rhein, Stadt','Mainz, kreisfreie Stadt','Neustadt an der Weinstrasse,St.','Pirmasens, kreisfreie Stadt','Speyer, kreisfreie Stadt','Worms, kreisfreie Stadt','Zweibruecken, kreisfreie Stadt','Alzey-Worms','Bad Duerkheim','Donnersbergkreis','Germersheim','Kaiserslautern','Kusel','Suedliche Weinstraße','Rhein-Pfalz-Kreis','Mainz-Bingen','Suedwestpfalz']
but_rlp = zieltabelle_gestapelt4[zieltabelle_gestapelt4["Region"].isin(liste_rlp)]
but_rlp.tail(30)
Out [25]:

Das Ergebnis lässt sich im obigen Tabellenausschnitt am Beispiel der kreisfreien Stadt Zweibrücken überprüfen (Zeile 727): Während in der ersten Variante unserer Tabelle ersichtlich wurde, dass die Daten für diese Raumeinheit nicht nach Altersgruppen differenziert vorliegen, wird in dieser zweiten Tabellenvariante über den Schlüssel "nz" die Gesamtzahl der Leistungsberechtigten aufgeführt.
Auch diese alternative Variante unseres Skripts fassen wir abschließend in einer einzelnen Zelle zusammen:
In [26]:
import pandas
import xlrd
# In der nächsten Zeile den Dateinamen anpassen
tabelle = pandas.read_excel('but-d-0-201909-xlsx.xlsx', sheet_name = '2 Leistungsarten', na_values = ['.','*'])
tabelle1 = tabelle.iloc[7:432]
tabelle2 = tabelle1.drop([9,10], axis = 0)
tabelle3 = tabelle2.drop(columns = ['Unnamed: 1'])
zieltabelle = tabelle3.drop(columns = ["Unnamed: 2"])
zieltabelle1 = zieltabelle.rename(columns = {"Unnamed: 3":"Insgesamt", "Unnamed: 0":"Region", "Unnamed: 4":"0_bis_5", "Unnamed: 5":"6_bis_14", "Grundsicherung für Arbeitsuchende nach dem SGB II":"15_bis_24"})
zieltabelle2 = zieltabelle1.drop([7,8,11], axis = 0)
tabelle_nan = zieltabelle2
tabelle_nan1 = tabelle_nan.dropna(axis = 0, subset = ['Insgesamt'])
tabelle_nan2 = tabelle_nan1.fillna(0)
tabelle_nan2["nz"] = tabelle_nan2["Insgesamt"] - tabelle_nan2["0_bis_5"] - tabelle_nan2["6_bis_14"] - tabelle_nan2["15_bis_24"]
tabelle_nan3 = tabelle_nan2.drop(columns = ["Insgesamt"])
# In der nächsten Zeile die Jahres- und Monatsangaben anpassen
tabelle_nan3.insert(1, "Monat", "09_2019")
liste = ["Monat", "Region"]
zieltabelle3 = tabelle_nan3.set_index(liste)
zieltabelle_gestapelt = zieltabelle3.stack(dropna = False)
zieltabelle_gestapelt1 = zieltabelle_gestapelt.reset_index()
zieltabelle_gestapelt2 = zieltabelle_gestapelt1.rename(columns = {"level_2":"Altersgruppe",0:"Leistungsberechtigte_BuT"})
zieltabelle_gestapelt3 = zieltabelle_gestapelt2[zieltabelle_gestapelt2.Leistungsberechtigte_BuT != 0]
umlaute = {"ä":"ae", "Ä":"Ae", "ö":"oe", "Ö":"Oe", "Ü":"Ue", "ü":"ue", "ß":"ss"}
zieltabelle_gestapelt4 = zieltabelle_gestapelt3.copy()
zieltabelle_gestapelt4["Region"].replace(umlaute, inplace = True, regex = True)
liste_rlp = ['Koblenz, kreisfreie Stadt','Ahrweiler','Altenkirchen (Westerwald)','Bad Kreuznach','Birkenfeld','Cochem-Zell','Mayen-Koblenz','Neuwied','Rhein-Hunsrueck-Kreis','Rhein-Lahn-Kreis','Westerwaldkreis','Trier, kreisfreie Stadt','Bernkastel-Wittlich','Eifelkreis Bitburg-Pruem','Vulkaneifel','Trier-Saarburg','Frankenthal (Pfalz), kr.f. St.','Kaiserslautern, kreisfr. Stadt','Landau in der Pfalz, kr.f. St.','Ludwigshafen am Rhein, Stadt','Mainz, kreisfreie Stadt','Neustadt an der Weinstrasse,St.','Pirmasens, kreisfreie Stadt','Speyer, kreisfreie Stadt','Worms, kreisfreie Stadt','Zweibruecken, kreisfreie Stadt','Alzey-Worms','Bad Duerkheim','Donnersbergkreis','Germersheim','Kaiserslautern','Kusel','Suedliche Weinstraße','Rhein-Pfalz-Kreis','Mainz-Bingen','Suedwestpfalz']
but_rlp = zieltabelle_gestapelt4[zieltabelle_gestapelt4["Region"].isin(liste_rlp)]
# In der nächsten Zeile den Dateinamen anpassen
but_rlp.to_csv("but_rlp_2019.csv", index = False, sep = ";")
Kommentiertes Notebook zum Download
datenaufbereitung.ipynb
Newsletter
Wenn Sie unseren Newsletter abonnieren möchten, füllen Sie bitte das folgende Formular vollständig aus.
Kontakt
Standort Potsdam
kobra.net, Kooperation in Brandenburg, gemeinnützige GmbH
Benzstr. 8/9, 14482 Potsdam
Ansprechpartner:
Tim Siepke, Leitung
0331 / 2378 5331
info@kommunales-bildungsmonitoring.de
Standort Trier
Kommunales Bildungsmanagement Rheinland-Pfalz - Saarland e.V.
Domfreihof 1a | 54290 Trier
Ansprechpartner:
Dr. Tobias Vetterle, Leitung
0651 / 4627 8443
info@kommunales-bildungsmonitoring.de
Dieses Vorhaben wird aus Mitteln des Bundesministeriums für Bildung und Forschung gefördert.